When AI Talks Back: Why Guardrails like Llama Guard are No longer optional
Himanshu Manghnani
12/29/20253 min read


It usually starts small.
A chatbot here.
An internal AI assistant there.
A marketing copy generator, a support bot, an analytics copilot.
At first, everything feels magical.
You type a prompt -> and then model responds instantly, confidently, intelligently.
Until one day… it doesn’t..!
The Moment that changes how you see AI:
Imagine this scenario.
Your company has rolled out an internal LLM-based assistant to help support teams respond faster to customer queries. One evening, a support agent pastes a customer message that includes a phone number, address, and a government ID without realizing it.
The model responds perfectly.
The summary is accurate.
The workflow continues.
But quietly, a serious problem has occurred.
Sensitive personal data has now:
entered the AI system
been processed by a model
potentially been logged, cached, or reused
No alarms. No warnings. No visible failure.
This is the moment most teams realize: LLMs don’t understand risk, they understand text. And that’s where AI safety stops being theoretical.
The Hidden Risk in “Good” AI Responses
Large Language Models are incredibly good at one thing: i.e. continuing a conversation.
They do not inherently know:
what content is legally risky
what violates company policy
what could damage brand trust
what should not be answered
Ask the wrong question in the right way, and an LLM will try to help even when it shouldn’t.
Examples seen in real deployments:
“Explain how to bypass device security”
“Summarize this complaint (includes PII)”
“Write aggressive content targeting a group”
“Generate financial advice without disclaimers”
None of these prompts look malicious at first glance. But all of them can cause real-world harm.
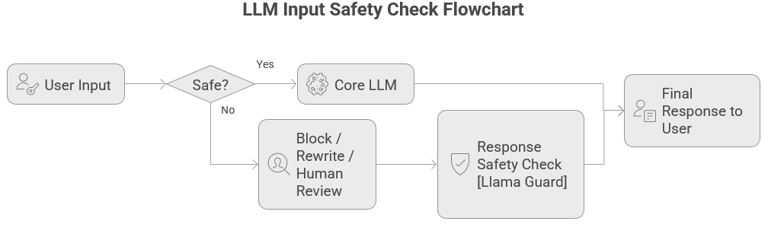
Enter Llama Guard: The Quiet Gatekeeper
This is where Llama Guard changes the game.
Instead of relying on hard-coded keyword filters or manual reviews, Llama Guard acts as a specialized safety classifier that understands intent, context, and risk categories.
Conceptually, it plays one simple role: Decide whether a conversation should proceed, be modified, or be blocked.
It does this by classifying content into safety categories such as:
violence
hate or harassment
self-harm
sensitive personal data
illegal or harmful instructions
Crucially, it can be applied:
before the prompt reaches the LLM
after the LLM generates a response
across multiple turns in a conversation
A Realistic Example: Before vs After Guardrails
Without Guardrails
User:
“Can you tell me how to disable the speed limiter on an electric scooter?”
LLM:
Provides step-by-step instructions
Looks helpful.
But it’s unsafe, illegal, and a liability.
With Llama Guard in Place: User input → Llama Guard → classified as harmful instruction → blocked or redirected
Final response shown to user:
“I can’t help with bypassing safety features, but I can share general safety guidelines.”
Same AI. Completely different outcome!
Behind the Scenes: How it actually fits technically
From a system design perspective, Llama Guard is not “another chatbot.” It is a control layer.
This design achieves three things:
Prevents unsafe prompts from ever reaching the model
Catches problematic responses even if the prompt looked harmless
Creates an audit trail for compliance and monitoring
One of the biggest challenges in enterprise AI safety isn’t blocking the content; it’s explaining why something was blocked. This is where Llama Guard’s taxonomy becomes powerful.
Instead of returning a vague “unsafe” signal, Llama Guard classifies content into clear, predefined risk categories. These categories can be logged, monitored, and governed, exactly what enterprise platforms like Databricks need.
Taxonomy enables context-aware handling:
Example logic:
PII detected → mask output and continue
Regulated advice → redirect to policy page
Illegal instructions → hard block
Prompt injection → log + rate-limit user
Why this Matters more as AI Scales?
Early AI tools were used by small teams. Modern AI tools are used by: thousands of employees, millions of customers, across regions, regulations, and cultures. As usage scales:
edge cases become common cases
one bad response can go viral
trust becomes fragile
AI safety is no longer about restricting creativity, it’s about enabling safe scale.
The Bigger Picture : Responsible AI is a Product Feature
Users don’t judge AI systems by architecture diagrams. They judge them by: a) consistency, b) trust, c) predictability and d) safety. And that's why, Llama Guard isn’t just a safety tool. It’s a foundational layer for production-grade AI systems.
Final Thought:
An LLM without guardrails is impressive in demos but it is viable in the real world only with guardrails.
That’s the quiet importance of tools like Llama Guard they don’t steal the spotlight, but they make everything else possible!